什么是连接池?
池,不由自主的会想到水池。小时候,我们都要去远处的水井挑水,倒进家中的水池里面。这样,每次要用水时,直接从水池中「取」就行了。不用大老远跑去水井打水。数据库连接池就如此,我们预先准备好一些连接,放到池中。当需要时,就直接获取。而不要每次跟数据库建立一个新的连接。特别对数据库连接这类耗时,耗资源的操作。当连接用完后,再放回池中,供后续使用。
连接池的作用?
避免多次去创建资源。例如,创建新的数据库连接,500ms 轻轻松松就消耗了。建立 TCP 连接,数据库账号验证等等。这性能消耗起来,可是非常大的。在稍大的系统内,连接池是必备的。同时,对技术人员要求,对连接池的掌握也是必须的。
tomcat-jdbc-pool 的特色
基于 jdk1.5 后的并发实现。代码简洁,精练。核心的类就2,3个。对池的控制就在 org.apache.tomcat.jdbc.pool.ConnectionPool 中搞定。
先前有简单看过 dbcp1.x, c3p0 等等,代码量真不少,逻辑复杂。想熟悉池的设计,可以仔细读读 tomcat-jdbc-pool,非常快速的入手。在 dbcp2 的实现时,跟 tomcat-jdbc-pool 思路一致(完全 copy 的版本)。对于连接池来说,最基本的特点就是:
有一定的容量,及已经创建好的对象
有「借」有「还」操作的接口
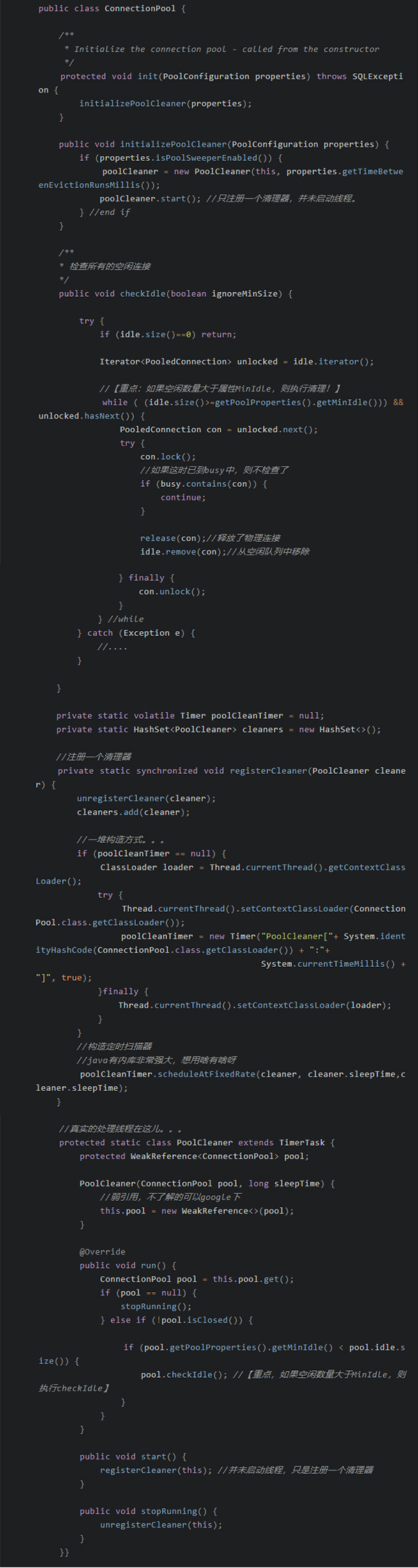
池中「借出」连接是怎么个过程?
在 jdbc-pool 设计有 2 队列,分别为 busy 和 idle,存储「正在使用」和「空闲」的连接。都采用 ArrayBlockingQueue 以保证线程安全。
当有请求「借」的动作过来时,从 idle 中 poll 一个连接,然后将该连接再 offer 至 busy 队列中。这是最基本最纯净的思路。
当 idle 连接不够时,内部会再去创建新的连接返回给客户端。
但是,做为「池」必须的职责之一是控制总量,不会任你去增长。那么,有意思来了,他是怎么控制总量的咧?我们可以通俗点称『占坑法』(tomcat 中也有不少场景采用这方式)。
首先池中有维护连接数总量「计数器」(采用 AtomicInteger 保证线程安全,每次新增或销毁都会变更)。『占坑法』就在每次要新创建连接池,先总量计数器+1(占位),再比较是否达到配置的池的最大连接数。如果没有达到,则创建新的;如果已达到了,则等待现有连接释放,再取走。有点类似,大学时先用本书去抢位置占着。大致实现代码【已经对源码简化】如下:
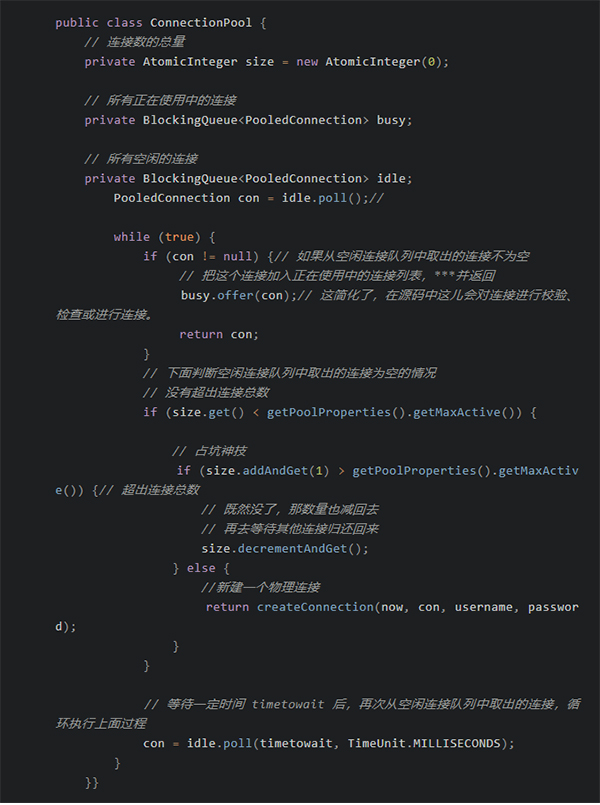
用完后「归还」连接是怎么个过程?
大致思路跟「借」操作相反落。当然是无视那些「善后」的工作,只关注资源的管理。但是,做为连接池必须的职责之一,并不真实的断开与数据库的连接。而只是放至 idle 队列中,供客户端下次再使用。如果有需要或必要肯定会释放,技巧所在。大致代码如下:
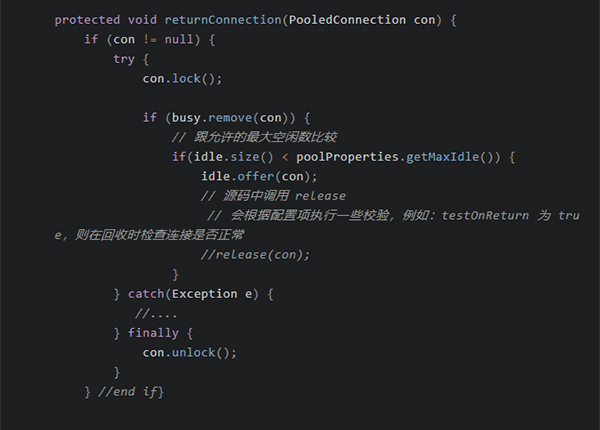
当长时间运行后,怎么回收无效的连接?
这是连接池必备的功能之一,类似检查死链或者释放自身过多的资源。比如,在高并发过后,对资源消耗量少时,就释放些不再使用的数据库连接(真实断开),维护合理的空格数量。【*** 连接池的minIdle定义了这个数量】
看到这应用场景就自然想到,通过后台线程定时扫描。——对的,就是这样子。」——同样在 ConnectionPool 这个类文件中的 PoolCleaner 类。写在同个类文件中,便于用 this 进行传递数据。不用再去构造个复杂的 ConnectionPool 对象。
直接上代码,「好代码」就是最好的描述。