一、 Condition
Condition是在java 1.5中才出现的,它用来替代传统的Object的wait()、notify()实现线程间的协作,相比使用Object的wait()、notify(),使用Condition1的await()、signal()这种方式实现线程间协作更加安全和高效。
阻塞队列实际上是使用了Condition来模拟线程间协作。
Condition是个接口,基本的方法就是await()和signal()方法;
Condition依赖于Lock接口,生成一个Condition的基本代码是lock.newCondition()
调用Condition的await()和signal()方法,都必须在lock保护之内,就是说必须在lock.lock()和lock.unlock之间才可以使用

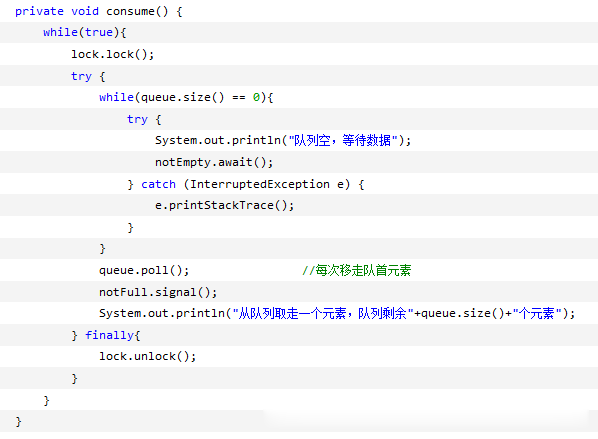
二、BlockingQueue
BlockingQueue通常用于一个线程生产对象,而另外一个线程消费这些对象的场景,一个线程往里边放,另外一个线程从里边取的一个BlockingQueue
非阻塞队列:不会对当前线程产生阻塞,面对类似消费者-生产者的模型时,就必须额外地实现同步策略以及线程间唤醒策略,这个实现起来就非常麻烦。
阻塞队列:会对当前线程产生阻塞,比如一个线程从一个空的阻塞队列中取元素,此时线程会被阻塞直到阻塞队列中有了元素。当队列中有元素后,被阻塞的线程会自动被唤醒(不需要我们编写代码去唤醒)。这样提供了极大的方便性。
阻塞队列使用最经典的场景就是socket客户端数据的读取和解析,读取数据的线程不断将数据放入队列,然后解析线程不断从队列取数据解析。
具体的实现类有LinkedBlockingQueue,ArrayBlockingQueued等。一般其内部的都是通过Lock和Condition来实现阻塞和唤醒。

三、volatile
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
四、 CAS
CAS(Compare and Swap),即比较并替换,实现并发算法时常用到的一种技术。
CAS的思想很简单:三个参数,一个当前内存值V、旧的预期值A、即将更新的值B,当且仅当预期值A和内存值V相同时,将内存值修改为B并返回true,否则什么都不做,并返回false。
五、多线程多线程的优点:
1)解决多任务同时执行的需求,合理使用CPU资源
2)程序设计在某些情况下更简单
3)程序响应更快
多线程的代价:
1)设计更复杂
在多线程访问共享数据的时候,这部分代码需要特别的注意。
2)上下文切换的开销
当CPU从执行一个线程切换到执行另外一个线程的时候,它需要先存储当前线程的本地的数据,程序指针等,然后载入另一个线程的本地数据,程序指针等,最后才开始执行。
3)增加资源消耗
线程在运行的时候需要从计算机里面得到一些资源。除了CPU,线程还需要一些内存来维持它本地的堆栈。
六、合理的配置线程池的大小CPU密集型任务应配置尽可能小的线程,如配置CPU个数+1的线程数,
IO密集型任务应配置尽可能多的线程,因为IO操作不占用CPU,不要让CPU闲下来,应加大线程数量,如配置两倍CPU个数+1,
线程池的作用:线程池作用就是限制系统中执行线程的数量。
根据系统的环境情况,可以自动或手动设置线程数量,达到运行的最佳效果;
少了浪费了系统资源,多了造成系统拥挤效率不高。
七、线程池● 等待队列:顾名思义,就是你调用线程池对象的submit()方法或者execute()方法,要求线程池运行的任务(这些任务必须实现Runnable接口或者Callable接口)。但是出于某些原因线程池并没有马上运行这些任务,而是送入一个队列等待执行。
● 核心线程:线程池主要用于执行任务的是“核心线程”,“核心线程”的数量是你创建线程时所设置的corePoolSize参数决定的。如果不进行特别的设定,线程池中始终会保持corePoolSize数量的线程数(不包括创建阶段)。
● 非核心线程:一旦任务数量过多(由等待队列的特性决定),线程池将创建“非核心线程”临时帮助运行任务。你设置的大于corePoolSize参数小于maximumPoolSize参数的部分,就是线程池可以临时创建的“非核心线程”的最大数量。这种情况下如果某个线程没有运行任何任务,在等待keepAliveTime时间后,这个线程将会被销毁,直到线程池的线程数量重新达到corePoolSize。
● maximumPoolSize参数也是当前线程池允许创建的最大线程数量。那么如果设置的corePoolSize参数和设置的maximumPoolSize参数一致时,线程池在任何情况下都不会回收空闲线程。keepAliveTime和timeUnit也就失去了意义。
● keepAliveTime参数和timeUnit参数也是配合使用的。keepAliveTime参数指明等待时间的量化值,timeUnit指明量化值单位。例如keepAliveTime=1,timeUnit为TimeUnit.MINUTES,代表空闲线程的回收阀值为1分钟。
八、线程池工作原理1、线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
2、当调用 execute() 方法添加一个任务时,线程池会做如下判断:
a. 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
b. 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列。
c. 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建线程运行这个任务;
d. 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会抛出异常,告诉调用者“我不能再接受任务了”。
3、当一个线程完成任务时,它会从队列中取下一个任务来执行。
4、当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
这样的过程说明,并不是先加入任务就一定会先执行。假设队列大小为 10,corePoolSize 为 3,maximumPoolSize 为 6,那么当加入 20 个任务时,执行的顺序就是这样的:首先执行任务 1、2、3,然后任务 4~13 被放入队列。这时候队列满了,任务 14、15、16 会被马上执行,而任务 17~20 则会抛出异常。最终顺序是:1、2、3、14、15、16、4、5、6、7、8、9、10、11、12、13。
九、线程池的等待队列工作队列的默认选项是 SynchronousQueue
在使用ThreadPoolExecutor线程池的时候,需要指定一个实现了BlockingQueue接口的任务等待队列。在ThreadPoolExecutor线程池的API文档中,一共推荐了三种等待队列,它们是:SynchronousQueue、LinkedBlockingQueue和ArrayBlockingQueue;
排队有三种通用策略:
1.直接提交。工作队列的默认选项是 SynchronousQueue,它将任务直接提交给线程而不保持它们。在此,如果不存在可用于立即运行任务的线程,则试图把任务加入队列将失败,因此会构造一个新的线程。此策略可以避免在处理可能具有内部依赖性的请求集时出现锁。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
2.无界队列。使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize 的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web 页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
3.有界队列。当使用有限的 maximumPoolSizes 时,有界队列(如 ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O 边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU 使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。





