
HDFS知识点总结(一)
2020-04-13
1、HDFS的设计
HDFS是什么:HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储超大文件,运行于商用硬件集群上,是管理网络中跨多台计算机存储的文件系统。
HDFS不适合用在:要求低时间延迟数据访问的应用,存储大量的小文件,多用户写入,任意修改文件。
2、HDFS的概念
HDFS数据块:HDFS上的文件被划分为块大小的多个分块,作为独立的存储单元,称为数据块,默认大小是64MB。
使用数据块的好处是:
一个文件的大小可以大于网络中任意一个磁盘的容量。文件的所有块不需要存储在同一个磁盘上,因此它们可以利用集群上的任意一个磁盘进行存储。
简化了存储子系统的设计,将存储子系统控制单元设置为块,可简化存储管理,同时元数据就不需要和块一同存储,用一个单独的系统就可以管理这些块的元数据。
数据块适合用于数据备份进而提供数据容错能力和提高可用性。
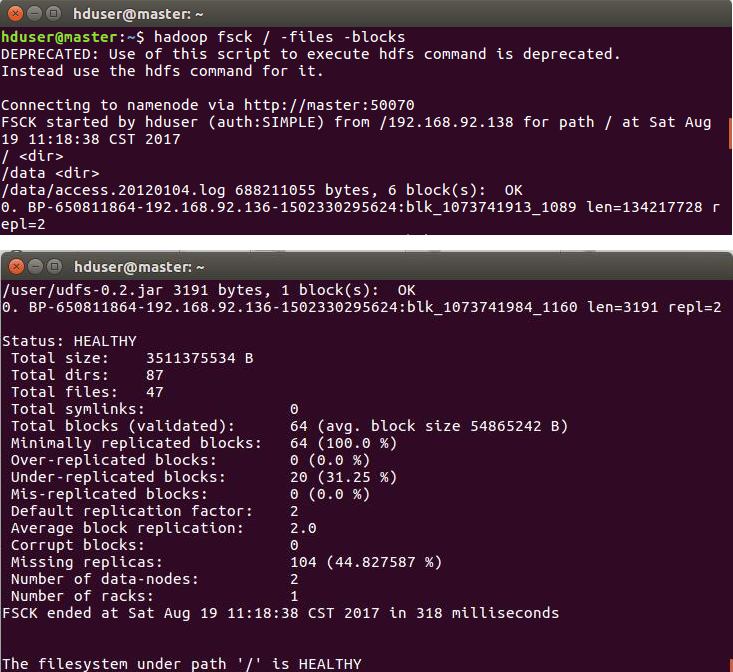
HDFS的三个节点:Namenode,Datanode,Secondary Namenode
Namenode:HDFS的守护进程,用来管理文件系统的命名空间,负责记录文件是如何分割成数据块,以及这些数据块分别被存储到那些数据节点上,它的主要功能是对内存及IO进行集中管理。
Datanode:文件系统的工作节点,根据需要存储和检索数据块,并且定期向namenode发送他们所存储的块的列表。
Secondary Namenode:辅助后台程序,与NameNode进行通信,以便定期保存HDFS元数据的快照。
HDFS Federation(联邦HDFS):
通过添加namenode实现扩展,其中每个namenode管理文件系统命名空间中的一部分。每个namenode维护一个命名空间卷,包括命名空间的源数据和该命名空间下的文件的所有数据块的数据块池。
HDFS的高可用性(High-Availability)
Hadoop的2.x发行版本在HDFS中增加了对高可用性(HA)的支持。在这一实现中,配置了一对活动-备用(active-standby)namenode。当活动namenode失效,备用namenode就会接管它的任务并开始服务于来自客户端的请求,不会有明显的中断。
架构的实现包括:
namenode之间通过高可用的共享存储实现编辑日志的共享。
datanode同时向两个namenode发送数据块处理报告。
客户端使用特定的机制来处理namenode的失效问题,这一机制对用户是透明的。
故障转移控制器:管理着将活动namenode转移给备用namenode的转换过程,基于ZooKeeper并由此确保有且仅有一个活动namenode。每一个namenode运行着一个轻量级的故障转移控制器,其工作就是监视宿主namenode是否失效并在namenode失效时进行故障切换。
3、命令行接口
两个属性项: fs.default.name 用来设置Hadoop的默认文件系统,设置hdfs URL则是配置HDFS为Hadoop的默认文件系统。dfs.replication 设置文件系统块的副本个数
文件系统的基本操作:hadoop fs -help可以获取所有的命令及其解释
常用的有:
hadoop fs -ls / 列出hdfs文件系统根目录下的目录和文件
hadoop fs -copyFromLocal <local path> <hdfs path> 从本地文件系统将一个文件复制到HDFS
hadoop fs -rm -r <hdfs dir or file> 删除文件或文件夹及文件夹下的文件
hadoop fs -mkdir <hdfs dir>在hdfs中新建文件夹
HDFS的文件访问权限:只读权限(r),写入权限(w),可执行权限(x)
4、Hadoop文件系统
Hadoop有一个抽象的文件系统概念,HDFS只是其中的一个实现。Java抽象接口org.apache.hadoop.fs.FileSystem定义了Hadoop中的一个文件系统接口。该抽象类实现HDFS的具体实现是 hdfs.DistributedFileSystem
5、Java接口
最简单的从Hadoop URL读取数据 (这里在Eclipse上连接HDFS编译运行)
Namenode:HDFS的守护进程,用来管理文件系统的命名空间,负责记录文件是如何分割成数据块,以及这些数据块分别被存储到那些数据节点上,它的主要功能是对内存及IO进行集中管理。
Datanode:文件系统的工作节点,根据需要存储和检索数据块,并且定期向namenode发送他们所存储的块的列表。
Secondary Namenode:辅助后台程序,与NameNode进行通信,以便定期保存HDFS元数据的快照。
HDFS Federation(联邦HDFS):
通过添加namenode实现扩展,其中每个namenode管理文件系统命名空间中的一部分。每个namenode维护一个命名空间卷,包括命名空间的源数据和该命名空间下的文件的所有数据块的数据块池。
HDFS的高可用性(High-Availability)
Hadoop的2.x发行版本在HDFS中增加了对高可用性(HA)的支持。在这一实现中,配置了一对活动-备用(active-standby)namenode。当活动namenode失效,备用namenode就会接管它的任务并开始服务于来自客户端的请求,不会有明显的中断。
架构的实现包括:
namenode之间通过高可用的共享存储实现编辑日志的共享。
datanode同时向两个namenode发送数据块处理报告。
客户端使用特定的机制来处理namenode的失效问题,这一机制对用户是透明的。
故障转移控制器:管理着将活动namenode转移给备用namenode的转换过程,基于ZooKeeper并由此确保有且仅有一个活动namenode。每一个namenode运行着一个轻量级的故障转移控制器,其工作就是监视宿主namenode是否失效并在namenode失效时进行故障切换。
3、命令行接口
两个属性项: fs.default.name 用来设置Hadoop的默认文件系统,设置hdfs URL则是配置HDFS为Hadoop的默认文件系统。dfs.replication 设置文件系统块的副本个数
文件系统的基本操作:hadoop fs -help可以获取所有的命令及其解释
常用的有:
hadoop fs -ls / 列出hdfs文件系统根目录下的目录和文件
hadoop fs -copyFromLocal <local path> <hdfs path> 从本地文件系统将一个文件复制到HDFS
hadoop fs -rm -r <hdfs dir or file> 删除文件或文件夹及文件夹下的文件
hadoop fs -mkdir <hdfs dir>在hdfs中新建文件夹
HDFS的文件访问权限:只读权限(r),写入权限(w),可执行权限(x)
4、Hadoop文件系统
Hadoop有一个抽象的文件系统概念,HDFS只是其中的一个实现。Java抽象接口org.apache.hadoop.fs.FileSystem定义了Hadoop中的一个文件系统接口。该抽象类实现HDFS的具体实现是 hdfs.DistributedFileSystem
5、Java接口
最简单的从Hadoop URL读取数据 (这里在Eclipse上连接HDFS编译运行)
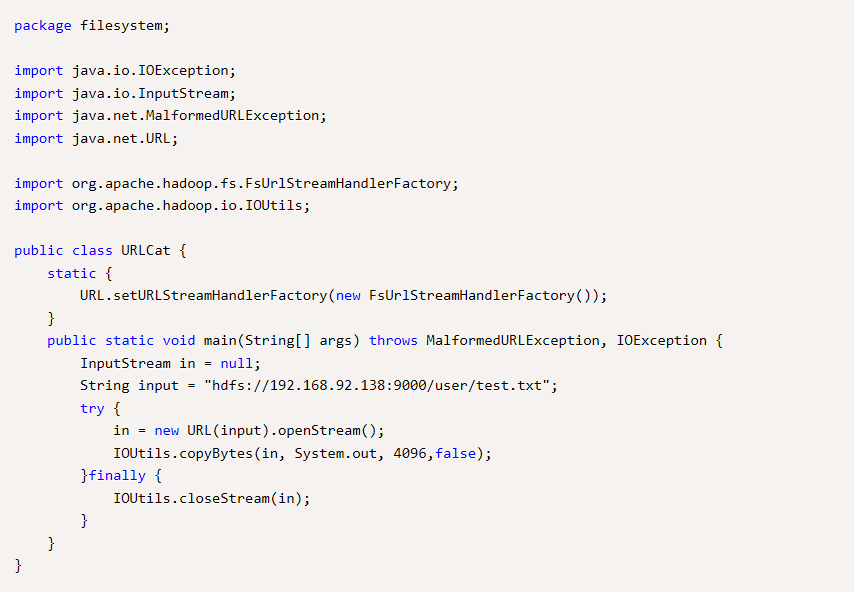
这里调用Hadoop的IOUtils类,在输入流和输出流之间复制数据(in和System.out)最后两个参数用于第一个设置复制的缓冲区大小,第二个设置结束后是否关闭数据流。
还可以通过FileSystem API读取数据
代码如下:
还可以通过FileSystem API读取数据
代码如下:

这里调用open()函数来获取文件的输入流,FileSystem的get()方法获取FileSystem实例。
使用FileSystem API写入数据
代码如下:
使用FileSystem API写入数据
代码如下:

FileSystem的create()方法用于新建文件,返回FSDataOutputStream对象。 Progressable()用于传递回掉窗口,可以用来把数据写入datanode的进度通知给应用。
使用FileSystem API删除数据
代码如下:
使用FileSystem API删除数据
代码如下:

FileSystem的其它一些方法:
public boolean mkdirs(Path f) throws IOException 用来创建目录,创建成功返回true。
public FileStatus getFileStates(Path f) throws FIleNotFoundException 用来获取文件或目录的FileStatus对象。
public FileStatus[ ] listStatus(Path f)throws IOException 列出目录中的内容。
public FileStatus[ ] globStatu(Path pathPattern) throws IOException 返回与其路径匹配于指定模式的所有文件的FileStatus对象数组,并按路径排序。
public boolean mkdirs(Path f) throws IOException 用来创建目录,创建成功返回true。
public FileStatus getFileStates(Path f) throws FIleNotFoundException 用来获取文件或目录的FileStatus对象。
public FileStatus[ ] listStatus(Path f)throws IOException 列出目录中的内容。
public FileStatus[ ] globStatu(Path pathPattern) throws IOException 返回与其路径匹配于指定模式的所有文件的FileStatus对象数组,并按路径排序。




