
ava中的堆内存算是整个内存区域中最重要的一块,几乎所有的对象都分配在堆内存。在堆内存中有两个主要的概念需要我们理解,这对分析java堆内存的故障有着重要的作用,分别是深堆和浅堆。
一、概念
我们先给出概念,然后再分析。
(1)浅堆表示一个java对象结构所占用内存的大小,这个java对象内部包含了三部分数据:对象头、实例数据和对齐填充。
(2)深堆表示一个java对象被 GC 回收后,可以真实释放的内存大小。
如果你有点疑惑,没关系。对上面出现的那些名词我们一个一个来解释。
1、对象头
一个对象分为三部分:对象头、实例数据、对齐填充。对象头又包含了两部分:标记部分和原始对象引用。
(1)标记部分:包括 hashcode、gc 分代年龄、锁状态标志、线程持有锁、偏向线程锁id,偏向时间戳,这一部分在32位机器上为 4 byte,64 位机器上为 8byte,一般来说我们的机器都是64位,所以现在默认指的是8个字节。
(2)原始对象引用是对象的指针,通过这个指针找到对象的实例,该数据可以压缩,32 位机器上为 4 byte,64位机器上为 8byte,jdk8默认开启压缩,大小为 4byte。
所以我们可以看到:一个java对象的对象头大小,没压缩的时候是16字节,压缩时候是12个字节。
2、实例数据
指的就是我们的java对象实例。这个很容易理解。
3、对齐填充
对齐填充要追根其根源,其实是到了计算机系统结构的学科。我在大学的时候学到了对齐填充,和这里是一样的道理。java中的对象都是以8个字节为单位对齐,所以每一个java对象的大小都是8的整数倍。
4、保留集
对象A能直接或者是间接访问其他的对象,这些对象集合起来就是A的保留集。当进行垃圾回收的时候,不仅回收A,也会回收保留集中所有的对象。
现在我们理解了这些基本的概念,再回过头来好好地看看,深堆和浅堆到底是什么?
浅堆指对象本身占用的内存,不包括其内部引用对象的大小。一个对象的深堆指只能通过该对象访问到的(直接或间接)所有对象的浅堆之和,即对象被回收后,可以释放的真实空间。在《实战java虚拟机》中,使用了一个案例,在这里引用一下:
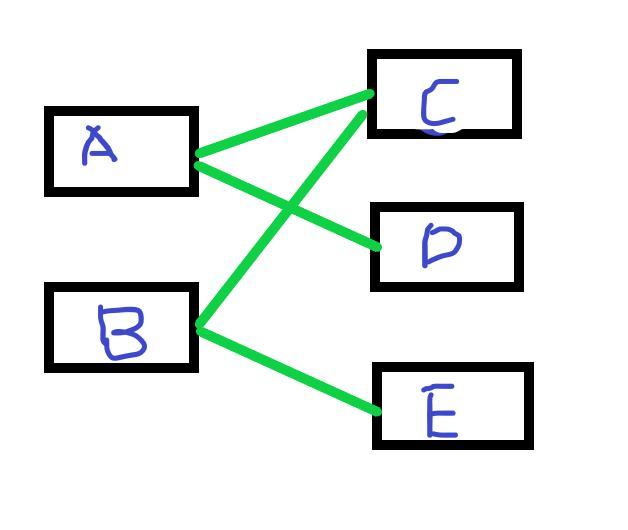
对象A引用了C和D,对象B引用了C和E。那么对象A的浅堆大小只是A本身,不含C和D,而A的实际大小为A、C、D三者之和。
而A的深堆大小为A与D之和,由于对象C还可以通过对象B访问到,因此不在对象A的深堆范围内。
我们再举一个例子来分析:1到100,被3整除的数可以送给对象A,被5整除的可以送给对象B。那么在程序退出时候,进行垃圾回收,此时对象A的的深堆肯定小于33,对象B的深堆肯定小于20,这是因为存在像15、30这样的数,既可以被3整除也可以被5整除,属于三不管对象。




