
10分钟搞懂zookeeper高可用集群(上)
2019-07-01
本文的目标人群是对 ZooKeeper 有一定了解的技术人员,将从 ZooKeeper 运行模式、集群组成、容灾和水平扩容四方面逐步深入,最终构建出高可用的 ZooKeeper 集群。zooKeeper 是 Apache 的一个顶级项目,为分布式应用提供高效、高可用的分布式协调服务,提供了诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知和分布式锁等分布式基础服务。由于 ZooKeeper 便捷的使用方式、卓越的性能和良好的稳定性,被广泛地应用于诸如 Hadoop、HBase、Kafka 和 Dubbo 等大型分布式系统中。
本篇文章将第一步讲解ZooKeeper的运行模式:
1-1单机模式:
1-1单机模式:
这种模式一般适用于开发测试环境,一方面我们没有那么多机器资源,另外就是平时的开发调试并不需要极好的稳定性。
在 Linux 环境下运行单机模式需要执行以下步骤:
1. 准备 Java 运行环境
安装 Java 1.6 或更高版本的 JDK,并配置好 Java 相关的环境变量 $JAVA_HOME 。
2. 下载 ZooKeeper 安装包
下载地址:http://zookeeper.apache.org/releases.html。选择最新的 stable 版本并解压到指定目录,我们用 $ZK_HOME 表示该目录。
3. 配置 zoo.cfg
首次使用 ZooKeeper,需要将 $ZK_HOME 下的 zoo_sample.cfg 文件重命名为 zoo.cfg,并进行以下配置:
tickTime=2000 ##Zookeeper最小时间单元,单位毫秒(ms),默认值为3000
dataDir=/var/lib/zookeeper ##Zookeeper服务器存储快照文件目录
dataLogDir=/var/lib/log ##Zookeeper服务器存储事务日志的目录
clientPort=2181 ##服务器对外服务端口,一般设置为2181
initLimit=5 ##Leader服务器等待Follower启动并完成数据同步的时间,默认值10,表示tickTime的10倍
syncLimit=2 ##Leader服务器和Follower之间进行心跳检测的最大延时时间,默认值5,表示tickTime的5倍
4. 启动服务
使用 $ZK_HOME/bin 目录下的 zkServer.sh 脚本进行服务的启动。
1-2集群模式
1-2集群模式
一个 ZooKeeper 集群通常由一组机器组成,一般 3 台以上就可以组成一个可用的 ZooKeeper 集群了。
组成 ZooKeeper 集群的每台机器都会在内存中维护当前的服务器状态,并且每台机器之间都会互相保持通信。
重要的一点是,只要集群中存在超过一半的机器能够正常工作,那么整个集群就能够正常对外服务。
ZooKeeper 的客户端程序会选择和集群中的任意一台服务器创建一个 TCP 连接,而且一旦客户端和服务器断开连接,客户端就会自动连接到集群中的其他服务器。
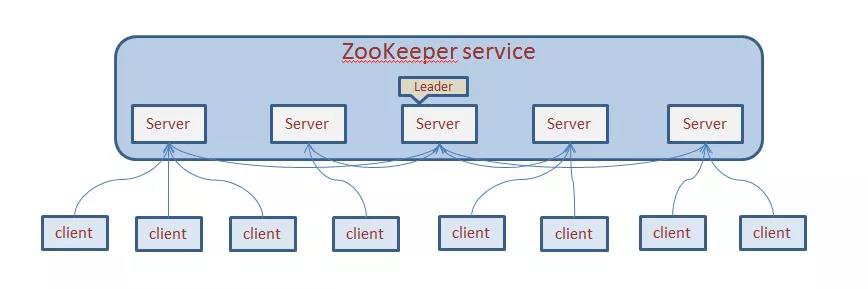
那么如何运行 ZooKeeper 集群模式呢?首先假如我们有三台服务器,IP 分别为 IP1、IP2 和 IP3,则需要执行以下步骤:
1. 准备 Java 运行环境(同上)
2. 下载 ZooKeeper 安装包(同上)
3. 配置 zoo.cfg
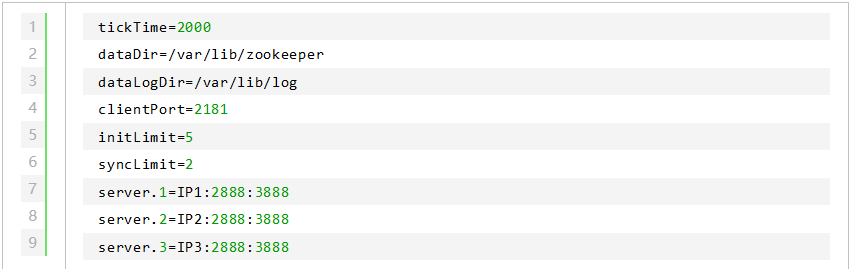
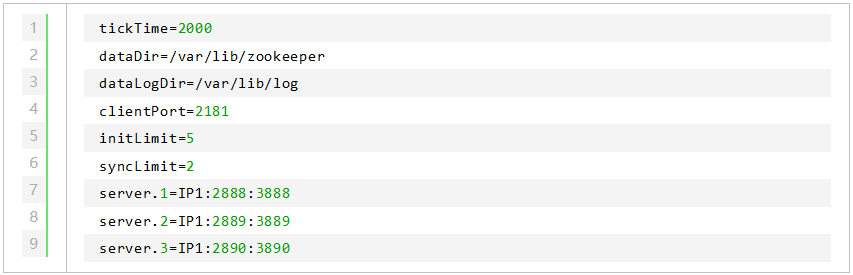
可以看到,相比于单机模式,集群模式多了 server.id=host:port1:port2 的配置。其中,id 被称为 Server ID,用来标识该机器在集群中的机器序号(在每台机器的 dataDir 目录下创建 myid 文件,文件内容即为该机器对应的 Server ID 数字)。host 为机器 IP,port1 用于指定 Follower 服务器与 Leader 服务器进行通信和数据同步的端口,port2用于进行 Leader 选举过程中的投票通信。
4. 创建 myid 文件
在 dataDir 目录下创建名为 myid 的文件,在文件第一行写上对应的 Server ID。
5. 按照相同步骤,为其他机器配置 zoo.cfg 和 myid文件
6. 启动服务
1-3伪集群模式
下期预告:集群组成、容灾、水平扩容
1-3伪集群模式
这是一种特殊的集群模式,即集群的所有服务器都部署在一台机器上。当你手头上有一台比较好的机器,如果作为单机模式进行部署,就会浪费资源,这种情况下,ZooKeeper允许你在一台机器上通过启动不同的端口来启动多个 ZooKeeper 服务实例,以此来以集群的特性来对外服务。
这种模式下,只需要把 zoo.cfg 做如下修改:
下期预告:集群组成、容灾、水平扩容




